Using Data Science to Predict NHL Outcomes
Project Overview
This project focuses on building and comparing multiple machine learning models to predict NHL game outcomes, leveraging both bookmaker odds and engineered in-game features. The analysis spans logistic regression (GLM), random forest, XGBoost, and neural networks, culminating in a meta-model ensemble for improved accuracy. Brief earlier experiments also explored player-level scoring predictions, but the main emphasis is on game-level predictions and betting analysis.
Methodology
Data Sources
- NHL API: Official team, game, and event data
- Bookmaker Odds: Scraped pre-game odds and implied probabilities
Feature Engineering
- Created dozens of engineered features capturing momentum, rest, team strengths, and contextual bookmaker information
- Data split to ensure prospective, non-leaky training and testing
Modeling & Evaluation
- Base Models: Generalized Linear Model (GLM), Random Forest, XGBoost, Neural Network
- Ensemble: Meta-model stacking for optimal performance
- Evaluation: Employed ROC AUC, calibration plots, and profit/loss analysis using simulated betting strategies to measure real-world value
- Used rolling-origin cross-validation to maintain a prospective forecast structure
Key Results
- Meta-ensemble model consistently outperformed individual base models on ROC AUC and real betting profit metrics
- Demonstrated the potential to identify market inefficiencies and optimize edge in sports betting
- Visualized calibration and ROC results to validate practical predictive utility
Tools & Technologies
- Languages: R, Python
- Frameworks: Tidymodels (R), Scikit-Learn, XGBoost, Keras/TensorFlow
- Visualization: ggplot2, Plotly, Matplotlib
Visualizations
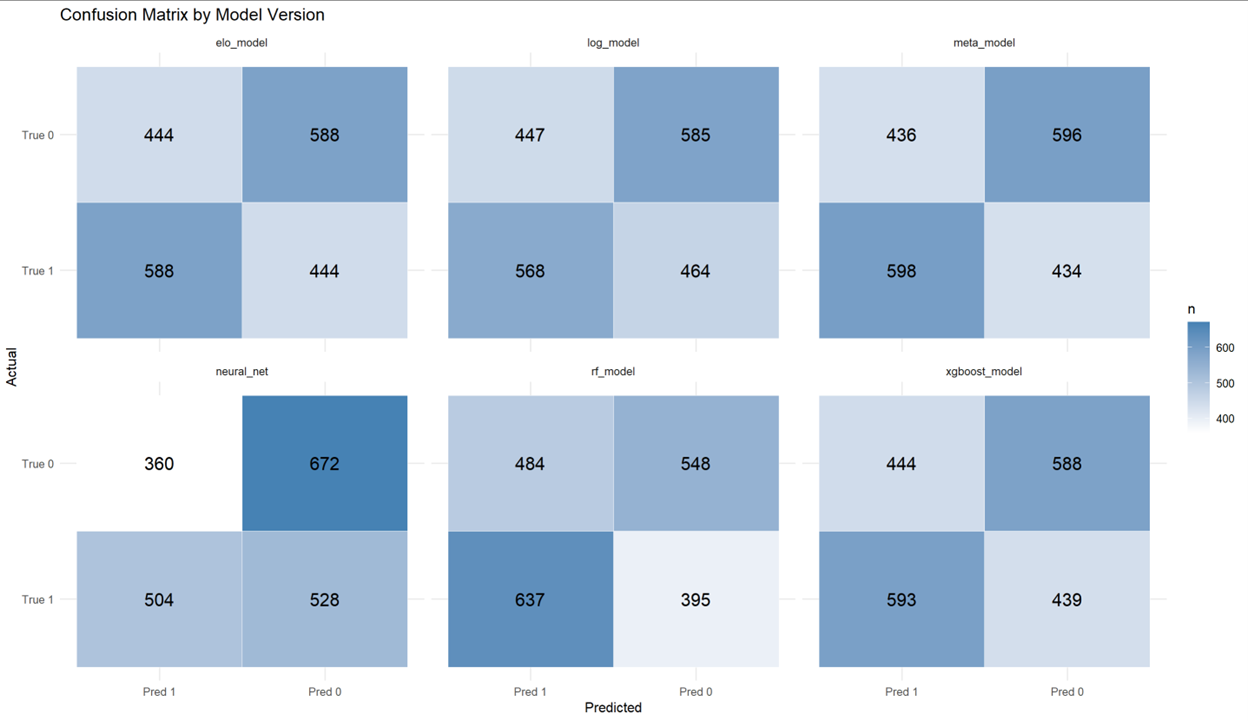
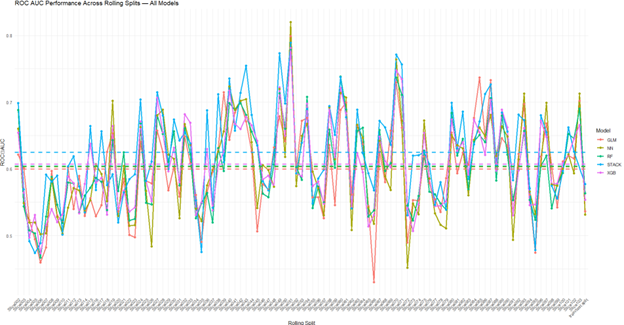
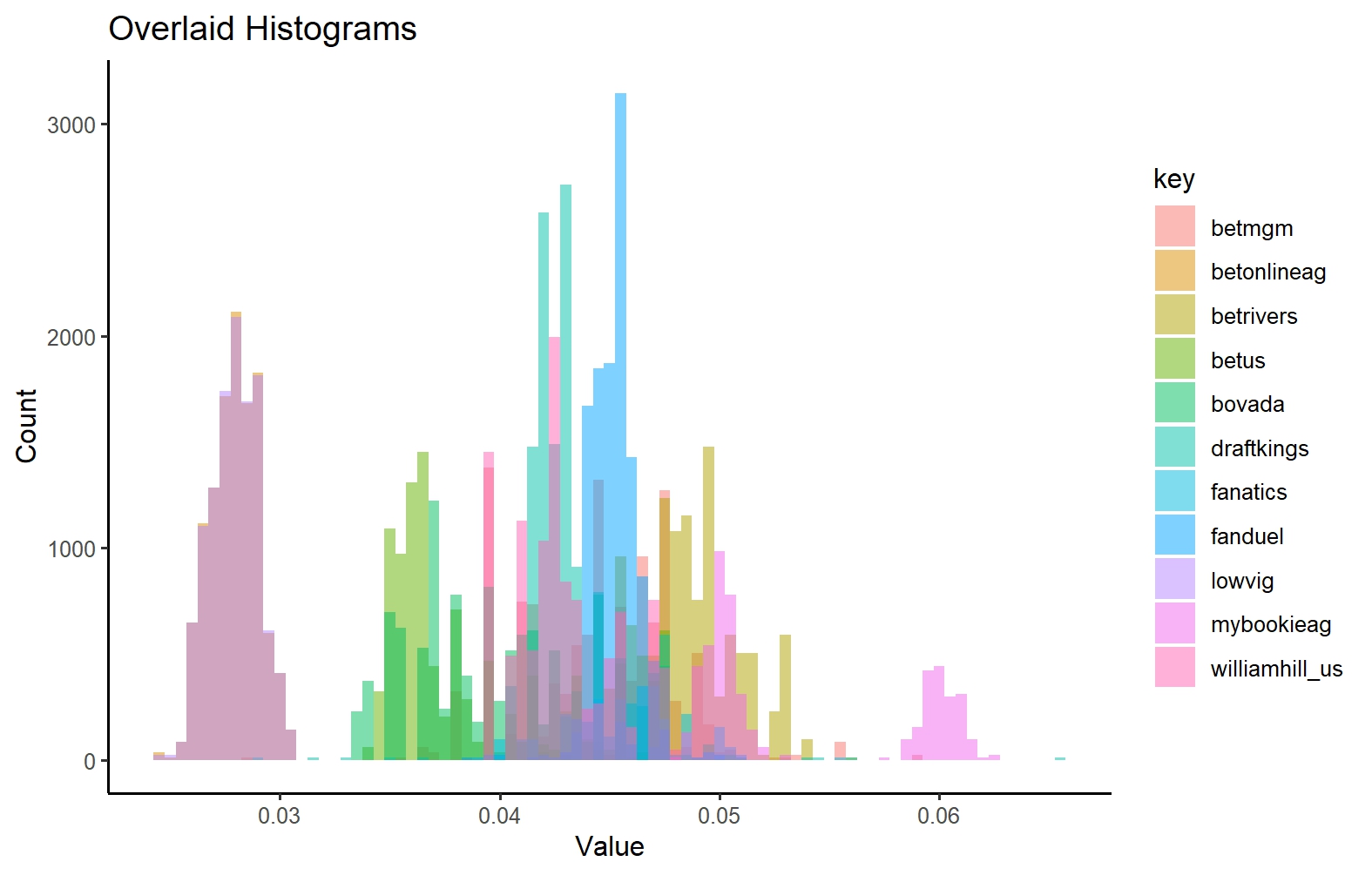
Application & Further Reading
Conclusion & Next Steps
- Model provided actionable signals for sports betting and identified bookmakers’ inefficiencies.
- Future work: Expand to live/in-play predictions, automate data ingestion, and refine ensemble meta-learning for additional sports and markets.